An associative array is an abstract data type used to store key-value pairs. Different languages have different data types for it:
- In Python — Dictionary
- In Ruby — Hash
- In Lua — Table
- In JavaScript — Object
- In Elixir and Java — Map
Associative arrays are popular in applied programming. They are convenient for representing compound data that contain many different parameters.
In a usual indexed array, we arrange values by indexes, which means that it can be put into memory as is. Things work differently with associative arrays. They do not have indexes to determine the order — so there's no easy way to get to the values. Associative arrays often use a hash table — a specific data structure to implement them.
A hash table allows you to organize the data of an associative array for convenient storage. A hash table uses an indexed array and a function to hash the keys. That said, a hash table isn't just a way to place data in memory; it involves logic.
In this lesson, we will discuss hash tables and learn how associative arrays work internally. You'll understand how many different processes go on in a program when we run this kind of simple code:
data = {}
data['key'] = 'value'
How do hash functions work
Any operation inside a hash table starts with converting the key somehow into an index of a regular array. To obtain an index from a key, you need to perform two actions:
- Find the hash, that is, hash the key
- Convert a key to an index — for instance, through the remainder of a division
Hashing is an operation that converts any input data into a string or a number of a fixed length. The function implementing the conversion algorithm is called a hash function. The result of hashing is called a hash or hash sum.
The most famous are CRC32, MD5, SHA, and many other types of hashing:
# Python has the zlib library, which contains the crc32 hashing algorithm
# This algorithm is convenient for clarity
import zlib
# Any data we want to hash is represented as a byte string
data = b'Hello, world!'
hash = zlib.crc32(data)
# hash is always the same for the same data
print(hash) # => 3957769958
We often encounter hashing in development. For example, the commit id in git 0481e0692e2501192d67d7da506c6e70ba41e913 is a hash resulting from hashing commit data.
When hashing, you first need to get a hash. It can then be converted into an array index — for example, to calculate the remainder of a division:
# It is to make sure that the indexes are not too big
# The bigger the size of the array, the more memory it takes up
index = abs(hash) % 1000 # modulo
print(index) # => 958
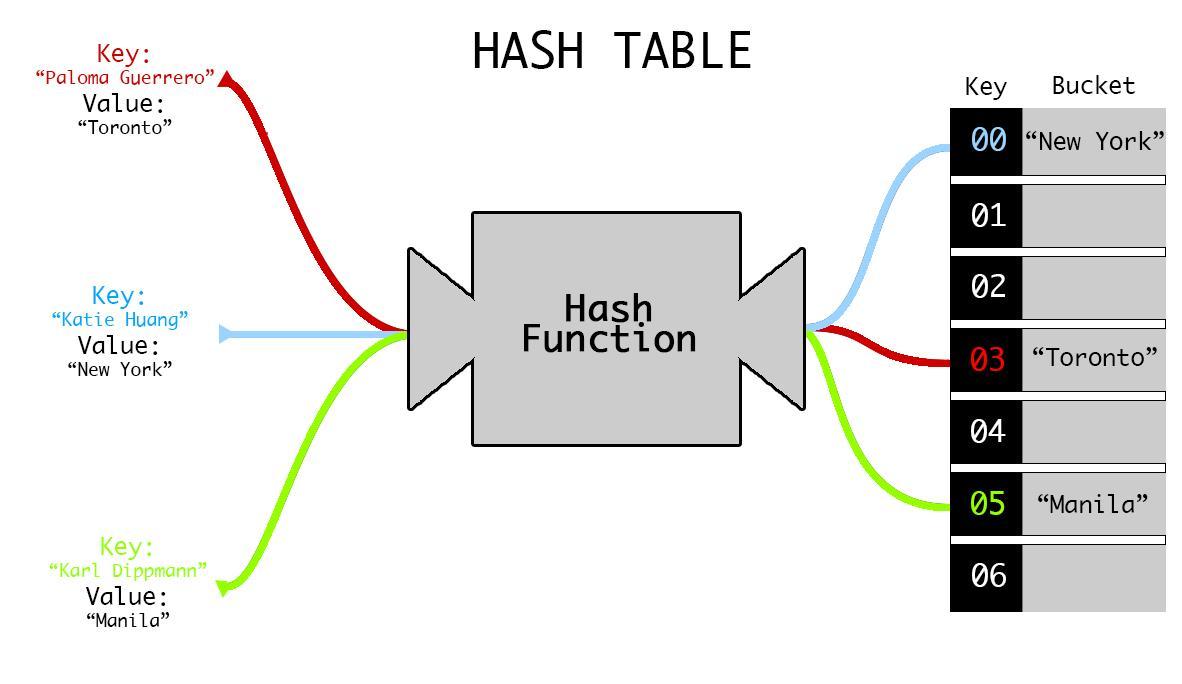
How hashing works from the inside
Let's look at how adding a new value to an associative array works. Let's write the following code:
data = {}
data['key'] = 'value'
Such simple code triggers a whole complex process. For simplicity, we will consider it in Python, although in reality, it all happens at a lower level.
Let's describe the hashing process without details and with simplifications:
We create an associative array and initialize the indexed array inside the interpreter:
internal = []Then we assign a value:
data['key'] = 'value'The interpreter then hashes the key. The result of the hashing is a number:
hash = zlib.crc32(b'key')The interpreter then takes the number from the previous step and converts it to an array index:
index = abs(hash) % 1000At the end, the interpreter searches for the index value of the internal indexed array and writes it into another array. In the new array, the first element is the
'key', and the second one is the'value':internal[index] = ['key', 'value']
Now let's see how reading data works:
data = {}
data['key'] = 'value'
print(data['key']) # => "value"
Let's look at how this code works from the inside:
The interpreter hashes the key. The result of the hashing is a number:
hash = zlib.crc32(b'key')The number obtained in the previous step is converted into an array index:
index = abs(hash % 1000)If the index exists, the interpreter extracts the array and returns it to the outside:
return internal[index] # ['key', 'value']
How collisions work
The key in the associative array can be a string of any length and content. But there is a contradiction here:
- All possible keys are an infinite set
- A hash function produces a fixed-length string as an output, meaning all output values are a finite set
It follows from the fact that not all input data will have a unique hash. At some point, duplicates may occur: several different values will lie under one hash. Developers refer to such situations as collisions. There are several ways of resolving conflicts. Each method has its type of hash table:
# Example of a collision
# The hash function returns the same hash for different line data
zlib.crc32(b'aaaaa0.462031558722291') # 1938556049
zlib.crc32(b'aaaaa0.0585754039730588') # 1938556049
The simplest way to resolve collisions is open addressing. It involves sequentially moving through the hash table slots, looking for the first free slot where we will write the value.
In the above example, open addressing works like this: the interpreter takes the second value and checks the 1938556050 hash. If it is busy, the interpreter will try to use the 1938556051 hash. This way, we will advance to the first unoccupied hash.
Collisions are not as rare as they may seem. If you learn it, you can study birthdays paradox.
Are there any more questions? Ask them in the Discussion section.
The Hexlet support team or other students will answer you.
- Article “How to Learn and Cope with Negative Thoughts“
- Article “Learning Traps“
- Article “Complex and simple programming tasks“
For full access to the course you need a professional subscription.
A professional subscription will give you full access to all Hexlet courses, projects and lifetime access to the theory of lessons learned. You can cancel your subscription at any time.




